
写在前面
环境配置
本地环境:
Python 3.7
IDE:Pycharm库版本:
numpy 1.18.1
pandas 1.0.3
sklearn 0.22.2
matplotlib 3.2.1
torch 1.10.1
tushare 1.2.60
backtrader 1.9.76.123代码实现
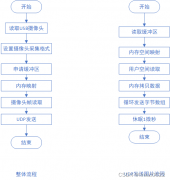
总体设计
为了实现这个基于深度学习模型的backtrader回测框架,我们可以将其分为以下模块:
数据获取模块:使用tushare库获取股票历史数据,并对数据进行预处理
深度学习模型模块:使用PyTorch创建一个基本的LSTM模型,通过滑动窗口的形式对股票历史数据进行训练以及测试,然后将训练好的模型进行保存,以便于回测框架的调用。
量化策略模块:基于Backtrader框架实现一个基于LSTM模型的简单交易策略。这个策略会在每天收盘时调用训练好的LSTM模型,预测后面的行情是否会上涨。如果预测上涨,那么就在明天以开盘价买入,如果下跌,就在明天以开盘价卖出。

数据获取
接下来,我们将实现一个函数来获取股票历史数据,请将tushareAPItoken替换到代码中的YOUR_API_TOKEN处。接下来,可以使用get_stock_data函数来获取指定股票的历史数据,然后将数据保存到本地,这里以招商银行两年的历史数据为例。
def get_stock_data(code, start_date, end_date, token):
ts.set_token(token)
pro = ts.pro_api()
df = pro.daily(ts_code=code, start_date=start_date, end_date=end_date)
df = df.sort_values(by="trade_date", ascending=True) # 对数据进行排序,以便滑动窗口操作
df.set_index("trade_date", inplace=True)
return df
stock_code = "600036.SH"
start_date = "20200101"
end_date = "20220101"
api_token = "YOUR_API_TOKEN"
data = get_stock_data(stock_code, start_date, end_date, api_token)
data.to_csv("./data.csv")
print(data.head())模型实现
这里用到了简单的LSTM模型进行测试,模型也没有进行进一步的调优,为了使模型具有更好的预测效果,以下是一些可能提高LSTM模型效果的方法:更改网络结构:增加层数或者增加隐藏单元数可以提高LSTM模型的表达能力。太多的层数或者隐藏单元数也可能导致过拟合,所以需要在训练集和测试集上做出合理的选择。加入正则化:LSTM模型也可以使用L2正则化等方法来避免过拟合。加入更多的特征:除了开盘价之外,也可以考虑加入其他的特征,例如最高价、最低价、成交量等,以提高模型的表达能力。调整超参数:可以通过网格搜索等方法来寻找最佳的超参数组合,例如学习率、batchsize、滑动窗口大小等。用到的LSTM模型代码如下:
class SimpleLSTM(nn.Module):
def __init__(self, input_size, hidden_size, num_layers, num_classes, dropout_rate=0.2):
super(SimpleLSTM, self).__init__()
self.hidden_size = hidden_size
self.num_layers = num_layers
self.rnn = nn.RNN(input_size, hidden_size, num_layers, batch_first=True)
self.fc1 = nn.Linear(hidden_size, hidden_size)
self.relu = nn.ReLU()
self.dropout = nn.Dropout(dropout_rate)
self.bn = nn.BatchNorm1d(hidden_size)
self.fc2 = nn.Linear(hidden_size, num_classes)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
h0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size)
out, _ = self.rnn(x, h0)
out = self.fc1(out[:, -1, :])
out = self.relu(out)
out = self.dropout(out)
out = self.bn(out)
out = self.fc2(out)
out = self.sigmoid(out)
return out接下来,我们需要对数据集进行划分,这里只用到了股票数据的收盘价来构建数据集。先对原始数据进行归一化处理,然后使用滑动窗口的形式输入过去一段时间的收盘价,以预测未来三天的收盘价是否会上涨,我们需要将数据转换成适用于模型训练的形式:
def create_dataset(stock_data, window_size):
X = []
y = []
scaler = MinMaxScaler()
stock_data_normalized = scaler.fit_transform(stock_data.values.reshape(-1, 1))
for i in range(len(stock_data) - window_size - 2):
X.append(stock_data_normalized[i:i + window_size])
if stock_data.iloc[i + window_size + 2] > stock_data.iloc[i + window_size - 1]:
y.append(1)
else:
y.append(0)
X, y = np.array(X), np.array(y)
X = torch.from_numpy(X).float()
y = torch.from_numpy(y).long()
return X, y, scaler之后,划分训练集跟测试集并对模型进行训练与测试,并对训练好的模型进行保存,以便于后面在backtrader策略中进行调用:
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
train_data = TensorDataset(X_train, y_train)
train_loader = DataLoader(train_data, batch_size=32, shuffle=True)
model = SimpleLSTM(input_size, hidden_size, num_layers, num_classes)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=1e-4)
num_epochs = 200
# 训练模型
for epoch in range(num_epochs):
for i, (batch_X, batch_y) in enumerate(train_loader):
outputs = model(batch_X)
loss = criterion(outputs, batch_y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (epoch + 1) % 10 == 0:
print(f"Epoch [{epoch + 1}/{num_epochs}], Loss: {loss.item():.4f}")
print("Finished Training")
torch.save(model.state_dict(), "lstm_model.pth")
model.eval()
with torch.no_grad():
correct = 0
total = 0
test_data = TensorDataset(X_test, y_test)
test_loader = DataLoader(test_data, batch_size=32, shuffle=False)
for batch_X, batch_y in test_loader:
outputs = model(batch_X)
_, predicted = torch.max(outputs.data, 1)
total += batch_y.size(0)
correct += (predicted == batch_y).sum().item()
print(f"Accuracy of the model on the test data: {100 * correct / total}%")backtrader策略实现
下面构建backtrader的策略,首先在Strategy中加载保存的模型,然后在next中每次收盘时对模型进行调用。需要注意的是这里通过滑动窗口的形式进行预测,所以定义了一个counter变量用来计算是否收集到了足够的数据。之后将窗口的数据进行归一化输入模型,并根据模型的预测结果来决定下一个交易的交易行为。这里的交易规则简单的定为,如果预测未来会上涨且没有仓位就在下一交易日开盘买入,如果预测未来会下跌且持有仓位就在下一交易日开盘卖出。回测时本金10000,每次交易只进行一手,佣金设置为万
# 构建策略
class LSTMStrategy(bt.Strategy):
def __init__(self):
self.data_close = self.datas[0].close
self.model = SimpleLSTM(input_size, hidden_size, num_layers, num_classes)
self.model.load_state_dict(torch.load("lstm_model.pth"))
self.model.eval()
self.scaler = scaler
self.counter = 1
def next(self):
if self.counter < window_size:
self.counter += 1
return
previous_close_prices = [self.data_close[-i] for i in range(0, window_size)]
X = torch.tensor(previous_close_prices).view(1, window_size, -1).float()
X = self.scaler.transform(X.numpy().reshape(-1, 1)).reshape(1, window_size, -1)
prediction = self.model(torch.tensor(X).float())
max_vals, max_idxs = torch.max(prediction, dim=1)
predicted_prob, predicted_trend = max_vals.item(), max_idxs.item()
if predicted_trend == 1 and not self.position: # 上涨趋势
self.order = self.buy() # 买入股票
elif predicted_trend == 0 and self.position: # 如果预测不是上涨趋势且持有股票,卖出股票
self.order = self.sell()
# Load test data
test_data = pd.read_csv("data.csv", index_col=0, parse_dates=True)
# Create a cerebro entity
cerebro = bt.Cerebro(runonce=False)
# Add data to cerebro
data = bt.feeds.PandasData(
dataname=test_data,
datetime=None,
open=1,
high=2,
low=3,
close=4,
volume=8,
openinterest=-1)
cerebro.adddata(data)
# Add strategy to cerebro
cerebro.addstrategy(LSTMStrategy)
# 本金10000,每次交易100股
cerebro.broker.setcash(10000)
cerebro.addsizer(bt.sizers.FixedSize, stake=100)
# 万五佣金
cerebro.broker.setcommission(commission=0.0005)
# Print out the starting conditions
print("Starting Portfolio Value: %.2f" % cerebro.broker.getvalue())
# Run over everything
cerebro.run()
# Print out the final result
print("Final Portfolio Value: %.2f" % cerebro.broker.getvalue())
# Plot the result
cerebro.plot()策略运行效果
对模型进行训练跟测试,经过多个epoch的迭代,训练的模型在测试集实现了66%的分类准确性。
Finished Training
Accuracy of the model on the test data: 66.3157894736842%之后调用backtrader回测引擎进行回测。回测结果的可视化如下所示,可以看出每次交易一手,回测结束后的资金是11689前期有多次亏损,中间模型捕捉到了一次大的上涨趋势,后面也是多次正的收益。

本文构建的交易策略使用了深度学习模型来构建交易信号,并通过backtrader框架实现量化回测。相比传统技术分析方法,使用深度学习模型可以更好地利用历史数据的信息,丰富交易策略。使用backtrader框架可以简化回测的流程,自动化交易决策,并且提供丰富的可视化工具,方便用户进行回测结果的分析和优化。这个框架只是简单将backtrader框架用于深度学习模型的历史回测,所以还有很多可以改进的地方,例如加入过滤条件,进行样本外测试,更换其他模型,引入更多特征等。总之,本文基于backtrader提供了一种基于深度学习构建回测框架的思路,感兴趣的读者可以基于此框架,对更多深度学习、机器学习模型进行测试。
本文内容仅仅是技术探讨和学习,并不构成任何投资建议。
获取完整代码与数据以及其他历史文章完整源码与数据可加入《人工智能量化实验室》知识星球。

《人工智能量化实验室》知识星球

文章为作者独立观点,不代表 股票程序化软件自动交易接口观点
相关文章



股民评论